Si el modelo, la escena o la carga de trabajo caben en la memoria de una sola tarjeta gráfica y no requieren procesamiento paralelo constante, normalmente basta con 1 GPU. 2 GPU sirven como primer paso hacia el escalado, 4 GPU suelen convertirse en la opción más equilibrada para inferencia, ajuste fino, renderizado y cargas mixtas, mientras que 8 GPU solo deberían elegirse cuando la tarea realmente puede utilizar todas las tarjetas y la infraestructura del servidor está preparada para los requisitos de alimentación, refrigeración, topología y licenciamiento de una plataforma de este tipo.
El número de tarjetas gráficas en un servidor no garantiza por sí solo el rendimiento. Un servidor con 8 GPU puede ser más lento o más caro por unidad de trabajo útil que un servidor con 4 GPU si el modelo no se divide bien entre las tarjetas, los datos se encuentran con un cuello de botella en PCIe, parte de las GPU permanecen inactivas o la refrigeración no permite mantener frecuencias estables.
La elección correcta no empieza con la pregunta “cuántas GPU caben en el chasis”, sino con otras preguntas:
- si el modelo, la escena o el perfil de usuario caben en la memoria de una GPU;
- si es más importante la latencia mínima de respuesta o el flujo total de solicitudes;
- si la tarea puede dividirse entre varias GPU sin grandes pérdidas;
- si se necesita comunicación rápida entre GPU mediante NVLink o NVSwitch;
- si la carga será constante o irregular;
- si conviene más un servidor grande o varios nodos más pequeños.
Para elegir tarjetas concretas, puedes orientarte por las GPU NVIDIA para servidores, pero el número de GPU debe calcularse después de analizar la carga, no antes.
Cuándo elegir 1, 2, 4 u 8 GPU
| Configuración | Cuándo encaja | Tareas típicas | Riesgo principal |
|---|---|---|---|
| 1 GPU | El modelo o la escena caben en la memoria de una tarjeta y la carga es moderada | inferencia LLM de prueba, desarrollo, renderizado pequeño, piloto VDI | falta de memoria de vídeo o ancho de banda cuando crece la carga |
| 2 GPU | Se necesita margen de memoria o más tareas simultáneas | dos copias del modelo, ajuste fino, renderizado, dos servicios independientes | comunicación débil entre GPU o falta de soporte multi-GPU en el software |
| 4 GPU | Se necesitan varias tareas paralelas y una distribución de recursos más flexible | inferencia por lotes, ajuste fino, granja de renderizado, VDI, trabajo de varios equipos | parte de las GPU puede quedar inactiva sin planificador y monitorización |
| 8 GPU | Una tarea pesada o una cola constante de tareas realmente utiliza todas las tarjetas | entrenamiento a gran escala, LLM grandes, inferencia densa, sistemas HGX | coste elevado, alimentación, refrigeración, complejidad operativa |
| Varios servidores | La carga se divide fácilmente en partes independientes y existe una red de baja latencia entre hosts | granja de renderizado, varios servicios de inferencia, pools VDI | es más difícil gestionar el clúster, la red y las actualizaciones |
Esta tabla ayuda a orientarse rápidamente, pero no sustituye el cálculo. Por ejemplo, 8 GPU son útiles para entrenar un modelo grande que se divide entre tarjetas e intercambia datos activamente entre ellas. Pero para una granja de renderizado, donde los fotogramas se calculan de forma independiente, varios servidores con 2–4 GPU pueden ser más cómodos y más resistentes a fallos.
También puede darse la situación contraria: una GPU potente con una gran cantidad de memoria de vídeo puede ser mejor que dos tarjetas más débiles. Si el modelo no puede distribuirse de forma eficiente entre varias GPU, añadir una segunda tarjeta no resolverá el problema de memoria y puede añadir latencia por intercambio de datos.
Cómo tomar la decisión

¿El modelo, la escena o el perfil de usuario caben en la memoria de una GPU?
Si la respuesta es sí, normalmente se puede empezar con una sola tarjeta. Esto es especialmente razonable para:
- prototipos de LLM;
- un asistente interno con carga moderada;
- un banco de pruebas para ajuste fino;
- un especialista 3D;
- un proyecto piloto de VDI;
- una pequeña cola de tareas de renderizado.
Si no cabe, hay que entender por qué falta memoria exactamente. A veces ayuda reducir la precisión de los cálculos, optimizar el modelo, acortar la longitud de contexto o trabajar con los datos de forma más cuidadosa. Pero si el modelo físicamente no cabe en una GPU, habrá que considerar tarjetas con más memoria o una configuración multi-GPU.
Para LLM grandes, a menudo son más importantes la capacidad y la velocidad de la memoria que el número de tarjetas por sí solo. Por ejemplo, NVIDIA H200 resulta interesante precisamente cuando el modelo y el contexto largo chocan con los límites de la memoria de vídeo y del ancho de banda de memoria. En la descripción oficial de NVIDIA H200 se indican 141 GB de HBM3e y un alto ancho de banda de memoria, por lo que estas tarjetas se consideran para grandes cargas LLM y HPC: NVIDIA H200.
¿Es más importante la latencia de una solicitud o el flujo total de tareas?
Para la inferencia LLM, esta es una de las preguntas clave.
Si es importante la latencia mínima de respuesta, no siempre conviene dividir un modelo entre varias GPU. La transferencia de datos entre tarjetas puede añadir latencia, especialmente si la comunicación se realiza solo a través de PCIe. En ese caso, puede ser mejor elegir una GPU más potente con más memoria de vídeo o 2 GPU con una buena topología.
Si lo más importante es el flujo total de solicitudes, la situación cambia. Se pueden ejecutar varias copias del modelo en distintas GPU, agrupar solicitudes en lotes y distribuir usuarios entre tarjetas. Entonces 4 GPU pueden aportar un buen incremento, porque cada tarjeta atiende su propia parte de la carga.
¿La carga es independiente o está estrechamente acoplada?
Las tareas independientes escalan con más facilidad. Entre ellas se incluyen:
- renderizado de fotogramas individuales;
- varios modelos independientes;
- servicios de inferencia separados;
- distintos equipos de desarrollo;
- usuarios VDI con perfiles diferentes;
- cargas de prueba y producción que pueden separarse entre distintas GPU.
Para estos escenarios no siempre hace falta un gran servidor con 8 GPU. A veces resulta más rentable usar 2–4 GPU en un servidor o varios nodos independientes con 1 GPU cada uno.
Las tareas estrechamente acopladas son más complejas. Aquí entran el entrenamiento de un modelo grande, la división de un LLM entre varias GPU o la inferencia de un modelo que no cabe en una sola tarjeta. En estos casos las GPU intercambian datos constantemente, por lo que no solo importa la potencia de las tarjetas, sino también cómo están conectadas entre sí. NVIDIA describe por separado el papel de NVLink y NVSwitch como comunicación de alta velocidad entre GPU para tareas en las que el intercambio de datos es crítico: NVIDIA NVLink.
¿Un servidor grande o varios más pequeños?
Un servidor grande es mejor si:
- el modelo debe funcionar como una sola tarea;
- se necesita intercambio rápido entre GPU;
- se usan 4–8 GPU con NVSwitch;
- la latencia entre nodos es crítica;
- el equipo sabe administrar una plataforma GPU densa.
Varios servidores más pequeños son mejores si:
- las tareas son independientes;
- se necesita tolerancia a fallos;
- la carga crece de forma gradual;
- distintos equipos utilizan perfiles de GPU diferentes;
- el renderizado o la inferencia pueden escalarse horizontalmente;
- la alimentación o la refrigeración en el rack son limitadas.
Para renderizado, VDI y varios servicios de inferencia independientes, el escalado horizontal suele ser más cómodo. Para entrenar un modelo grande o ejecutar inferencia LLM pesada, un servidor con la interconexión GPU adecuada puede ser más eficiente.
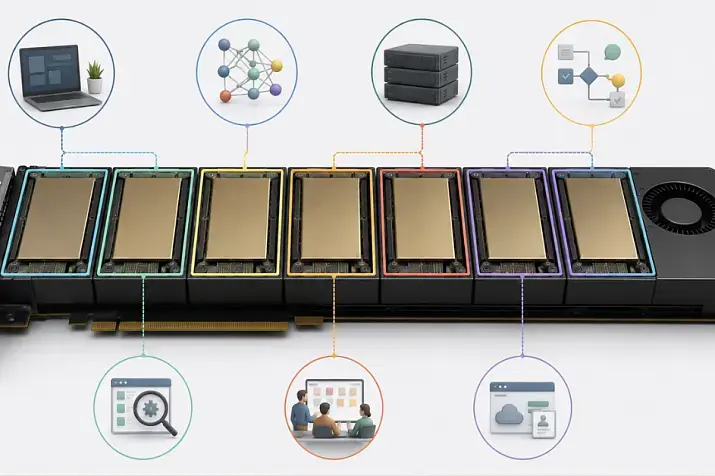
Cómo utilizan varias GPU las distintas tareas

PowerEdge R760xa. Fuente de la imagen: ServerMall
Dell describe PowerEdge R760xa como un servidor refrigerado por aire para entrenamiento de IA/ML, inferencia, analítica y VDI.
Inferencia LLM
La inferencia es la ejecución de un modelo ya entrenado: respuestas de un chatbot, análisis de documentos, generación de código, clasificación o búsqueda en una base de conocimiento. Para los LLM no solo importan los cálculos, sino también la memoria: el modelo, el contexto y los datos intermedios deben alojarse en algún lugar.
En la elección del número de GPU influyen:
- el tamaño del modelo;
- la longitud de contexto;
- el número de usuarios simultáneos;
- los requisitos de latencia de respuesta;
- la capacidad de memoria de vídeo;
- la velocidad de la memoria;
- la posibilidad de ejecutar varias copias del modelo;
- el soporte de procesamiento por lotes de solicitudes.
1 GPU es adecuada si el modelo cabe en la memoria de la tarjeta, hay pocos usuarios y la latencia es más importante que el flujo máximo. Es una buena opción para un asistente interno, un piloto o un servicio con carga irregular.
2 GPU son necesarias si el modelo casi cabe en una tarjeta, se requiere margen de memoria o hay que ejecutar dos copias independientes del servicio. Pero aquí es importante comprobar si el software elegido admite la división del modelo entre GPU.
4 GPU suelen ser cómodas para inferencia en producción, cuando hay varios modelos, un flujo estable de solicitudes o diferentes grupos de usuarios. Se puede asignar una GPU a un modelo, la segunda a otro, la tercera a pruebas y la cuarta a reserva o carga pico.
8 GPU se justifican para modelos grandes e inferencia densa, cuando existe una cola constante de solicitudes y el software sabe distribuir el modelo entre las tarjetas. En la documentación de NVIDIA Triton y TensorRT-LLM se trata por separado el despliegue multi-GPU y multi-node de grandes modelos de lenguaje en Kubernetes.
Entrenamiento y ajuste fino de modelos
El entrenamiento desde cero es la tarea más pesada para las GPU. El ajuste fino suele requerir menos recursos, pero también puede depender de la memoria de vídeo, la velocidad de intercambio entre GPU y la preparación de los datos.
Hay varias formas de escalar.
Paralelismo de datos.
Cada GPU recibe su parte de los datos, calcula el resultado y después se sincronizan los parámetros. Es un enfoque comprensible y extendido, pero al aumentar el número de GPU el intercambio de datos puede empezar a limitar la aceleración.
División del modelo entre GPU.
El modelo se divide en partes. Este enfoque es necesario cuando no cabe en la memoria de una sola tarjeta. Aquí son especialmente importantes NVLink, NVSwitch y la topología correcta del servidor.
Ejecución en canalización.
Diferentes partes del modelo se ejecutan por turno en distintas GPU. Esto ayuda con modelos grandes, pero requiere una configuración cuidadosa. De lo contrario, algunas tarjetas esperarán a que otras terminen su etapa.
Para experimentos y ajuste fino pequeño, a menudo basta con 1 GPU. Para las primeras pruebas multi-GPU y lotes más grandes se pueden usar 2 GPU. Para un equipo que ajusta modelos con regularidad, 4 GPU suelen convertirse en un mínimo de trabajo. 8 GPU hacen falta cuando hay experimentos pesados constantes, grandes conjuntos de datos y una metodología clara para distribuir la carga.
Las tarjetas de nivel NVIDIA A100 80GB suelen considerarse una opción universal para inferencia, ajuste fino y tareas donde la memoria HBM es importante. Para escenarios de entrenamiento más pesados e inferencia LLM conviene mirar hacia H100/H200. En las especificaciones oficiales de NVIDIA H100 se indican variantes SXM y PCIe, soporte de MIG y NVLink, por lo que al elegir es importante mirar no solo el nombre de la GPU, sino también el factor de forma concreto.
Renderizado
El renderizado escala de forma distinta a los LLM. Si el proyecto puede dividirse en fotogramas o escenas independientes, varias GPU o servidores separados pueden ser más rentables que un nodo denso con 8 GPU.
1 GPU es adecuada para un especialista, un estudio pequeño o un servidor donde las escenas caben en la memoria de la tarjeta. 2 GPU pueden acelerar el renderizado si el motor sabe utilizar varias tarjetas de forma eficiente. 4 GPU son una buena opción para una pequeña granja donde se pueden distribuir tareas. 8 GPU se justifican con una carga constante, pero requieren mucha atención a la alimentación, la refrigeración y las licencias del motor de renderizado.
El renderizado tiene una limitación importante: si la escena no cabe en la memoria de una GPU, añadir una segunda tarjeta no siempre resuelve el problema. En algunos motores, cada GPU debe tener el conjunto completo de datos de la escena en su propia memoria. Por eso, antes de comprar, hay que comprobar cómo trabaja exactamente el software elegido con varias GPU.
Para cargas mixtas —renderizado, visualización, inferencia, gráficos y aplicaciones de ingeniería— pueden servir tarjetas como NVIDIA L40S 48GB o NVIDIA RTX PRO 6000 Blackwell Server Edition. Estas GPU suelen ser interesantes no solo para redes neuronales, sino también para cargas gráficas.
VDI y cargas multiusuario
VDI son puestos de trabajo virtuales a los que los usuarios se conectan mediante escritorios remotos o estaciones virtuales. En estos proyectos no solo importa el rendimiento de la GPU, sino también la previsibilidad: un usuario no debe quedarse con todos los recursos de los demás.
Para VDI hay que tener en cuenta:
- los perfiles de usuario;
- el tipo de aplicaciones: ofimática, CAD, 3D, ingeniería, visualización;
- la posibilidad de dividir la GPU entre usuarios;
- el soporte de vGPU;
- las licencias;
- la compatibilidad con el hipervisor;
- la monitorización de la carga por usuario.
1 GPU sirve para un piloto o un grupo pequeño. 2 GPU permiten separar distintos perfiles de usuario. 4 GPU ya ofrecen un servidor VDI más denso. 8 GPU tienen sentido para una plataforma grande, pero solo si se han calculado de antemano las licencias, los perfiles y la carga real. En la documentación de NVIDIA se describen los productos con licencia y la configuración de licenciamiento para escenarios vGPU.
Qué limita a un servidor multi-GPU
| Limitación | Por qué es importante | Qué comprobar antes de comprar |
|---|---|---|
| Memoria de vídeo | El modelo, la escena o el perfil de usuario pueden no caber en una GPU | capacidad de memoria, tipo de memoria, posibilidad de optimizar el modelo |
| NVLink/NVSwitch | Son necesarios para un intercambio rápido entre GPU | qué GPU están conectadas directamente, si existe NVSwitch |
| Topología PCIe | No todas las ranuras son iguales en velocidad y latencia | esquema de ranuras, root complex, NUMA, switch PCIe |
| Líneas CPU | Las GPU requieren suficientes líneas PCIe | procesador, chipset, distribución de líneas por ranuras |
| RAM | La memoria CPU es necesaria para datos, caché y preparación de tareas | capacidad de RAM, frecuencia, ubicación NUMA |
| Almacenamiento | Las GPU quedan inactivas si los datos llegan demasiado despacio | NVMe, RAID, velocidad del dataset, red de almacenamiento |
| Alimentación | 4–8 GPU aumentan bruscamente los requisitos de las fuentes de alimentación | TDP total, margen de potencia, redundancia |
| Refrigeración | Cuando se sobrecalientan, las GPU reducen sus frecuencias | factor de forma del servidor, flujo de aire, tarjetas pasivas o activas |
| Red | Para varios servidores es importante el intercambio entre nodos | 25/100/200/400 GbE, InfiniBand, latencia |
| Licencias | VDI y el software profesional pueden licenciarse por separado | vGPU, motores de renderizado, hipervisor, planificador de tareas |
Un servidor multi-GPU no es solo un chasis con varias tarjetas gráficas. Es un sistema conectado en el que GPU, CPU, memoria, discos, red, alimentación, refrigeración y software deben corresponderse entre sí. Si un componente es mucho más débil que los demás, las GPU caras esperarán datos, se sobrecalentarán, permanecerán inactivas o trabajarán por debajo del nivel esperado.
1 GPU: cuándo basta con una sola tarjeta gráfica
Un servidor con 1 GPU no es necesariamente una opción débil. Para muchas tareas es el punto de partida más racional, especialmente si el proyecto aún no tiene una carga estable.
1 GPU es adecuada para:
- prototipado de LLM;
- inferencia de prueba;
- un chatbot interno;
- ajuste fino de modelos pequeños;
- un especialista 3D;
- un piloto VDI;
- tareas donde importan la simplicidad y el precio.
Ventajas de esta configuración:
- es más fácil configurar controladores y entorno;
- hay menos requisitos para el servidor;
- menor consumo eléctrico;
- refrigeración más sencilla;
- menos riesgos de compatibilidad;
- es más fácil entender el perfil real de la carga.
Las limitaciones también son claras:
- una GPU puede topar rápidamente con el límite de memoria de vídeo;
- un servicio puede ocupar toda la tarjeta;
- no hay reserva cuando crece la carga;
- es más difícil atender a varios equipos o proyectos.
Si el proyecto acaba de empezar, 1 GPU suele ofrecer el mejor equilibrio entre precio y facilidad de gestión. Aun así, es importante no elegir “cualquier tarjeta”, sino una que encaje por memoria, refrigeración, factor de forma y soporte del software necesario.
2 GPU: primer paso hacia el escalado
2 GPU son una buena opción intermedia entre un servidor sencillo y una plataforma multi-GPU completa. Encajan cuando una tarjeta ya no basta, pero pasar a 4 u 8 GPU todavía no está justificado.
2 GPU son útiles si hay que:
- ejecutar dos modelos independientes;
- aumentar el número de solicitudes simultáneas;
- dividir un modelo grande entre dos tarjetas;
- acelerar el renderizado;
- probar entrenamiento multi-GPU;
- separar carga de producción y experimentos.
Antes de comprar hay que comprobar:
- si se utilizarán GPU iguales;
- si existe NVLink para ese par concreto de tarjetas;
- si hay suficientes líneas PCIe;
- si las GPU no están detrás de CPU distintas sin tener en cuenta NUMA;
- si el software admite trabajar con dos GPU;
- si no conviene más una sola tarjeta con más memoria de vídeo.
2 GPU pueden aportar un incremento notable si las tareas son independientes o el software paraleliza bien la carga. Pero si el modelo se divide mal, la segunda tarjeta puede no resolver el problema. Además, el intercambio entre GPU a veces añade latencia y la configuración final no funciona tan rápido como se esperaba.
4 GPU: opción equilibrada para muchas tareas
4 GPU suelen convertirse en la configuración más práctica para empresas que ya necesitan un rendimiento serio, pero aún no necesitan la complejidad de una plataforma con 8 GPU.
Este servidor es adecuado para:
- inferencia por lotes;
- varios servicios LLM;
- ajuste fino de modelos medianos y grandes;
- un equipo de desarrollo ML;
- una pequeña granja de renderizado;
- VDI con varios perfiles de usuario;
- carga mixta donde parte de las GPU se dedica a inferencia y parte a experimentos.
Ventajas de 4 GPU:
- los recursos son más fáciles de distribuir entre tareas;
- menor riesgo de comprar un sistema sobredimensionado;
- es más fácil cargar todas las tarjetas con trabajo útil;
- menos requisitos de alimentación y refrigeración que en 8 GPU;
- se pueden usar las GPU como un único pool o como dispositivos independientes.
Desventajas:
- la topología PCIe ya importa;
- se necesita monitorización de la carga;
- hay que planificar colas de tareas;
- los errores en la distribución de carga provocan GPU inactivas;
- sin disciplina operativa, el servidor se convierte rápidamente en una “caja común” donde no está claro quién usa qué.
Si la empresa tiene varios modelos para inferencia, ajuste fino periódico y tareas gráficas separadas, 4 GPU suelen ser más útiles que 8 GPU. Es más fácil cargarlas de forma uniforme, mantenerlas y escalar después.
8 GPU: cuándo está realmente justificado
8 GPU no son una opción universalmente “mejor”, sino una configuración especializada para tareas capaces de utilizar una plataforma multi-GPU densa.
8 GPU son necesarias si hay:
- entrenamiento de modelos grandes;
- ajuste fino pesado;
- LLM grandes que requieren división entre GPU;
- flujo constante de solicitudes de inferencia;
- tareas HPC;
- sistemas HGX con NVSwitch;
- un equipo capaz de administrar estos servidores.
Antes de elegir 8 GPU hay que comprobar:
- factor de forma de las tarjetas: PCIe o SXM;
- presencia de NVLink o NVSwitch;
- qué GPU están conectadas directamente;
- requisitos del rack y de alimentación eléctrica;
- disipación de calor;
- compatibilidad del servidor con GPU concretas;
- requisitos de red si el servidor formará parte de un clúster;
- licencias de software;
- monitorización de temperatura, memoria, carga y errores.
Un servidor con 8 GPU tiene sentido cuando la tarea es una sola, grande y se paraleliza bien, o cuando existe una cola constante de tareas independientes. Si la carga es irregular, parte de las tarjetas quedará inactiva y el coste de propiedad seguirá siendo alto.
Para cargas de IA densas, como entrenamiento e inferencia grande, a menudo se considera NVIDIA H100 80GB, pero al elegir hay que comparar no solo la GPU, sino toda la plataforma: interconexión, alimentación, refrigeración, soporte de controladores y modo de operación previsto.
Por qué 8 GPU no siempre son más rápidas ni más rentables que 4 GPU

La aceleración no crece de forma lineal
Si el número de GPU se duplica, la tarea no está obligada a ejecutarse el doble de rápido. En la práctica, parte del tiempo se gasta en:
- sincronización;
- transferencia de datos entre GPU;
- espera de la CPU;
- preparación de datos;
- trabajo con memoria;
- limitaciones internas del framework.
Cuantas más GPU participan en una tarea, más importante se vuelve el intercambio entre ellas. Si la comunicación es lenta, se pierde parte de la aceleración.
El modelo puede no utilizar todas las tarjetas
Un modelo pequeño no será mejor solo porque se ejecute en 8 GPU. Si cabe en una tarjeta y no requiere un flujo enorme de solicitudes, las demás GPU permanecerán inactivas o ejecutarán tareas demasiado pequeñas.
Para inferencia, a menudo es más rentable ejecutar varias copias del modelo en GPU separadas que intentar extender un solo modelo a todas las tarjetas. Pero esto solo funciona si hay suficientes solicitudes.
La memoria de vídeo no se suma automáticamente
No se puede simplemente multiplicar 8 GPU por 80 GB y considerar que se ha obtenido una sola tarjeta gráfica de 640 GB. Cada GPU tiene su propia memoria. Para usar varias tarjetas como un único recurso, se necesitan enfoques especiales de división del modelo, soporte del framework y una topología correcta.
Si la tarea no sabe trabajar con memoria distribuida, añadir GPU no resolverá el problema de falta de memoria.
El servidor se vuelve más caro de operar
Un servidor con 8 GPU no solo cuesta más al comprarlo. También aumentan los gastos permanentes:
- electricidad;
- refrigeración;
- requisitos del rack;
- coste del tiempo de inactividad;
- complejidad de diagnóstico;
- precio de un error de configuración;
- requisitos de cualificación de los administradores.
Si una plataforma con 8 GPU permanece inactiva o trabaja al 30–40% de carga, económicamente puede ser peor que varios servidores más pequeños.
Varios servidores a veces son más fiables
Para tareas independientes, varios servidores con 2–4 GPU pueden ser más cómodos que un gran nodo. Si un servidor falla, los demás siguen trabajando. Se puede comprar equipo gradualmente, separar equipos y planificar el mantenimiento con más facilidad.
Un servidor grande gana cuando se necesita una conexión densa entre GPU. Varios servidores ganan cuando la carga se divide fácilmente.
Cuándo es mejor usar varios servidores en lugar de uno grande
Conviene considerar varios servidores si:
- las tareas son independientes;
- hay muchos servicios de inferencia pequeños;
- el renderizado se divide por fotogramas;
- los usuarios VDI pueden distribuirse por pools;
- se necesita tolerancia a fallos;
- el equipo se compra de forma gradual;
- distintos equipos usan perfiles de GPU diferentes.
Un servidor grande es mejor si:
- el modelo no cabe en una GPU;
- se necesita una conexión rápida entre tarjetas;
- se usa NVSwitch;
- se entrena un modelo grande;
- la latencia entre nodos es crítica;
- hay un equipo que sabe mantener esta plataforma.
Por ejemplo, para una granja de renderizado, cuatro servidores con 2 GPU pueden ser más prácticos que un servidor con 8 GPU. Las tareas son independientes, el fallo de un nodo no detiene toda la granja y el escalado puede hacerse gradualmente. Para entrenar una LLM grande, un servidor de 8 GPU con la topología correcta puede ser mejor porque los datos se transfieren constantemente entre GPU.
Ejemplos de configuraciones para tareas reales

Asistente LLM interno
Para un asistente interno de empresa, normalmente no hace falta comprar 8 GPU desde el principio. Primero basta con entender el modelo, el número de usuarios y los requisitos de latencia.
Enfoque:
- 1 GPU, si el modelo es compacto y hay pocos usuarios;
- 2 GPU, si se necesita margen de memoria o más solicitudes paralelas;
- 4 GPU, si hay varios modelos, carga estable y asistentes distintos para diferentes departamentos;
- varios servidores, si los servicios son independientes y se necesita tolerancia a fallos.
Qué comprobar:
- longitud de contexto;
- número pico de solicitudes;
- requisitos de latencia;
- posibilidad de optimizar el modelo;
- crecimiento de la carga en 6–12 meses.
Inferencia de varios modelos en un producto
Si el producto utiliza varios modelos, una GPU grande no siempre es más cómoda. A menudo es mejor distribuir los modelos entre distintas tarjetas y gestionar las colas.
Enfoque:
- 2 GPU, para dos modelos independientes o separación producción/pruebas;
- 4 GPU, como opción base para varios servicios;
- 8 GPU, solo con carga alta y constante;
- varios servidores, si los modelos son independientes y se necesita escalado horizontal.
Qué comprobar:
- si se pueden ejecutar varias copias del modelo;
- si se necesita aislamiento de clientes;
- cómo se distribuyen las solicitudes;
- si existe un planificador de tareas;
- cómo calcular el coste de una solicitud.
Ajuste fino de LLM
El ajuste fino puede ser ligero o muy pesado: todo depende del tamaño del modelo, los datos y el método de adaptación.
Enfoque:
- 1 GPU, para experimentos y modelos pequeños;
- 2 GPU, para las primeras pruebas multi-GPU;
- 4 GPU, como configuración de trabajo para un equipo;
- 8 GPU, para experimentos pesados constantes y modelos grandes.
Qué comprobar:
- volumen de datos;
- tamaño del batch;
- requisitos de precisión de cálculo;
- velocidad de intercambio entre GPU;
- capacidad de RAM;
- velocidad de NVMe;
- preparación del pipeline de datos.
Renderizado y gráficos 3D
Para renderizado es importante cómo utiliza varias GPU el motor concreto. Algunas tareas se dividen bien por fotogramas, otras se topan con la memoria de una tarjeta.
Enfoque:
- 1 GPU, para una estación de trabajo o un servidor pequeño;
- 2 GPU, para acelerar el renderizado si el motor lo admite;
- 4 GPU, para una pequeña granja;
- varios servidores, si las tareas son independientes;
- 8 GPU, solo con carga constante e infraestructura preparada.
Qué comprobar:
- si el motor admite varias GPU;
- si la escena cabe en la memoria de una tarjeta;
- si hay limitaciones de licencia;
- cómo se distribuyen los fotogramas;
- si se necesita modo interactivo o solo renderizado final.
VDI y estaciones de trabajo virtuales
Para VDI importan no las pruebas de pico, sino la estabilidad por usuario. El servidor debe soportar la jornada laboral, aplicaciones distintas y carga irregular.
Enfoque:
- 1 GPU, para un piloto;
- 2 GPU, para separar perfiles de usuario;
- 4 GPU, para un servidor VDI de trabajo;
- 8 GPU, para un gran pool de usuarios con perfiles calculados de antemano.
Qué comprobar:
- tipos de usuarios;
- requisitos de CAD, 3D y aplicaciones de ingeniería;
- licencias vGPU;
- compatibilidad del hipervisor;
- monitorización de carga por usuario;
- reglas de limitación de recursos.
Lista de comprobación antes de comprar un servidor GPU
Sobre la tarea
- ¿Cuál es la carga principal: inferencia, entrenamiento, renderizado, VDI o escenario mixto?
- ¿El modelo o la escena caben en la memoria de una GPU?
- ¿Es más importante la latencia o el flujo total de tareas?
- ¿La carga es constante o irregular?
- ¿Se puede dividir la tarea entre GPU sin perder mucha eficiencia?
- ¿Se necesita aislamiento de equipos, clientes o usuarios?
Sobre el servidor
- ¿Cuántas líneas PCIe están disponibles?
- ¿Cuál es la topología de las GPU?
- ¿Hay NVLink o NVSwitch?
- ¿Hay suficiente RAM?
- ¿Bastan NVMe y la velocidad de almacenamiento?
- ¿Hay suficientes fuentes de alimentación?
- ¿El chasis admite la refrigeración necesaria?
- ¿Hay margen en rack, alimentación eléctrica y ruido?
Sobre el software
- ¿El framework admite multi-GPU?
- ¿Se necesitan licencias vGPU?
- ¿Hay limitaciones del motor de renderizado?
- ¿Existe un planificador de tareas?
- ¿Cómo se medirá la carga de las GPU?
- ¿Cómo se calculará el coste de una hora GPU o de una solicitud?
Sobre la operación
- ¿Quién monitorizará las GPU y cómo?
- ¿Cómo se actualizarán los controladores?
- ¿Qué hacer si falla una tarjeta?
- ¿Cómo escalar dentro de un año?
- ¿Qué es más barato: añadir GPU a un servidor o comprar un segundo nodo?
- ¿Hay reserva de alimentación y refrigeración?
FAQ

¿Hay que comprar 8 GPU para LLM?
No siempre. Si el modelo cabe en una GPU y hay pocas solicitudes, 8 GPU permanecerán inactivas. 8 GPU son necesarias para modelos grandes, inferencia densa o entrenamiento donde existe escalado multi-GPU real.
¿Se suma la memoria de vídeo de varias GPU?
No automáticamente. Cada GPU tiene su propia memoria. Usar varias tarjetas como un único recurso solo es posible con una división correcta del modelo y soporte del framework.
¿Qué es mejor: 4 GPU en un servidor o 4 servidores con 1 GPU?
Para tareas independientes suelen ser más cómodos varios servidores. Para un modelo grande o entrenamiento, es mejor un servidor con conexión rápida entre GPU.
¿Cuándo se necesita NVLink o NVSwitch?
Cuando las GPU deben intercambiar datos con frecuencia: entrenamiento, división del modelo, inferencia LLM pesada. Para tareas independientes, como el renderizado de fotogramas separados, NVLink puede ser menos crítico.
¿Sirve 1 GPU para renderizado?
Sí, si las escenas caben en la memoria de la GPU y no hay una cola constante de tareas. Para una granja conviene considerar 2–4 GPU o varios servidores separados.
¿Qué es más importante para LLM: el número de GPU o la memoria de vídeo?
Primero, la memoria de vídeo. Si el modelo no cabe, el número de GPU ayuda solo con una división correcta del modelo. Si el modelo cabe, el número de GPU es más importante para el rendimiento total y el procesamiento paralelo de solicitudes.
¿Se pueden mezclar distintas GPU en un servidor?
Técnicamente a veces se puede, pero para entrenamiento, inferencia y renderizado esto suele crear problemas: distintos volúmenes de memoria, distinta velocidad, matices diferentes de controladores y carga desigual. Para cargas de producción normalmente es más seguro usar GPU iguales o separar de antemano tarjetas distintas para tareas distintas.
Cómo elegir el número de GPU
1 GPU debería elegirse si la tarea cabe en la memoria de una tarjeta, la carga es moderada y la simplicidad es más importante que la máxima escalabilidad.
2 GPU son adecuadas cuando se necesita el primer paso hacia el escalado: más solicitudes simultáneas, dos modelos independientes, aceleración del renderizado o pruebas de un enfoque multi-GPU.
4 GPU son la opción más universal para muchas empresas. Esta configuración sirve para inferencia, ajuste fino, renderizado, VDI y cargas mixtas si existe un planificador y una distribución clara de la carga.
8 GPU son necesarias para tareas que realmente utilizan una plataforma multi-GPU densa: entrenamiento grande, LLM grandes, inferencia por lotes constante, plataformas HGX con la topología correcta e infraestructura preparada.
Varios servidores son mejores si la carga es independiente, se necesita tolerancia a fallos y la empresa quiere escalar gradualmente.
El mejor servidor GPU no es el que tiene más tarjetas gráficas, sino aquel en el que cada GPU está ocupada de forma estable con trabajo útil y no se topa con límites de memoria, red, alimentación, refrigeración o software.